Build Your Private LLM Applications
Build, customize, and deploy powerful LLM models effortlessly—no code required, complete control guaranteed.
We help every enterprise fully utilize its AI capabilities through our automation
You just need to install our platform and run it on your dataset in any environment
Automation




Data Privacy
Developers choose where to train and deploy LLM models. We are environment-agnostic and follow security best practices.


Cost
Customers save costs with flexible resource use, including infrastructure and models that require less GPU time.
Governance


Resiliency


Control
AI engineers can easily benchmark models for higher accuracy and prevent LLM errors like hallucinations, denied topics, and harmful content.
We automated a no-code, zero-code platform from data ingestion, training, inferencing to deployment.
We built a governance center for product owners to track LLM model development, auditing, and performance.
DevOps best practices are implemented to ease integration, reduce latency, and enhance the high availability of deployed models.
LLMOps Platform
LLM adoption has been widespread across data-driven organizations of all sizes. The demand for pre-trained models is high, with some organizations training their own models if the budget allows. Privacy, ownership, and SLAs are major concerns for companies, who prefer an architecture-agnostic approach with the flexibility to lift and shift as needed.
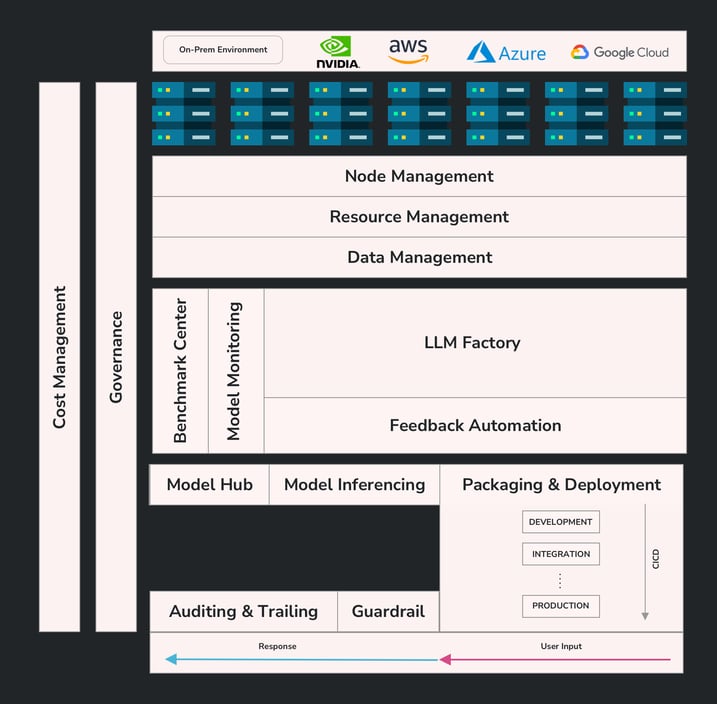
Our solution is a multi-faceted LLMOps platform that helps developers with data acquisition and preparation, utilizes different modalities for model training (RAG, Prompt Engineering, Fine-Tuning, Full Training), evaluates performance, automates model inference, and integrates the LLM solution into products through systematic CI/CD.
Our platform accelerates this process by 270% at 10x less cost. Below, we cover the main building blocks of our solution.




AI Flow Automation
LLM Factory
LLM Factory begins with LLM model building, supporting various architectural patterns such as prompt engineering, RAG, fine-tuning, and pre-training existing models. Developers can select these patterns based on the dataset size and LLM models they wish to use. We assist developers in finding the best-performing models on Hugging Face that meet their generative AI requirements, with the option to bring their own LLM models as well.
Our platform leverages state-of-the-art transformer-based fine-tuning approaches, significantly reducing computational and storage costs. We provide all the utilities AI engineers need for their use cases. For instance, for question answering or semantic search, we offer free and optimized embeddings and vector stores. For prompt engineering, we utilize all in-context learning best practices for prompt execution and analytics within a streamlined design.
In summary, LLM Factory equips developers with the tools and flexibility to build, fine-tune, and deploy high-performing LLM models efficiently, ensuring they can meet diverse AI requirements with reduced costs and enhanced capabilities.
Continuous Feedback Automation
We help users evaluate the quality of model responses by providing different scoring functions tailored to various use cases. Our automated input and output ranking and rating process is trustworthy and leverages advanced annotation techniques to quantify results accurately.
This data is used as comparison data, and our automation continuously trains the model in a learning fashion to enhance performance until the desired criteria are met
Benchmark Center
Throughout the LLM factory pipeline, various model metrics are captured. We identify the use case and collect more than 40 metrics to ensure the model quality, such as accuracy, BLEU, perplexity, SPICE, and others.
Model Inferencing
Inferencing is one of the important steps post-training. We select the fine-tuned model metrics at this step. Most LLM projects will utilize the RAG technique for modeling. Once the wrapper is finalized and evaluated by the AI engineers, it will be packaged and pushed as a Docker image to our repository.
We value microservice architecture and have built our application stack based on this framework. Once model inferences are built and ready to be used, we containerize the models and inferences using wrappers, then upload them to model hub repositories for deployment. Deployments are carried out within the Kubernetes cluster, allowing us to manage the high availability and resiliency of the API development. We utilize a CI/CD pipeline on GitLab or GitHub to deploy and validate the application stack across development, test, staging, and production environments. For production and disaster recovery (DR) environments, we provide various deployment strategies such as blue-green deployment, A/B testing, and canary releases.
Model Packaging & Deployment

AI Orchestration
Resource Management
We have built node exporters that can be installed on each server. Through our exporters, we manage and orchestrate the servers. To increase operability and efficiency between servers and training jobs, it is necessary to install a Kubernetes cluster if one does not already exist. We monitor resources such as CPU, GPU, memory, GPU memory, and storage read/write throughput. AI engineers can book and prioritize the resources required for training via our platform, receiving alerts if the monitored metrics exceed thresholds.
Data Management
We will handle data governance and storage management. AI engineers specify the data to be exported for the project, along with its requirements and any necessary transformations for structured or unstructured data. For instance, in a chatbot project, our transformation job can convert text into a series of question-answer pairs needed for training jobs. Once the requirements are met, wrappers are prepared for data serving in API, stream, and batch formats.
Our AI partners help us scale this platform


Training Up Office
2108 North Street Suite N Sacramento, CA95816, US
info@trainingup.ai